Unpack on Arrival
Rendering means two things on the web. Which one happens first determines whether your content exists for AI crawlers, search bots, and readers alike.


I sat in enough meetings where a developer explained why the new site needed to be built in React. The arguments were good. Component reusability. A single codebase. The ecosystem. The talent pool. All of it technically defensible, some of it genuinely compelling.
I kept choosing tools that delivered tangible markup. HTML, ready on arrival, with the content already in it.
What rendering actually means
Here is where the terminology gets slippery, and it is worth pausing on because the confusion is load-bearing.
When most people hear "rendering" they think of the browser: pixels appearing on screen, a page becoming visible. That instinct is correct. The browser always renders in that sense. But the web industry borrowed the word for a second meaning, and the two have been quietly creating confusion ever since.
The question client-side versus server-side rendering is actually asking is: who assembles the HTML before the browser gets it? A server-side rendered site sends complete HTML in its first response. The content is there, in the markup, before the browser does anything. A client-side rendered site, the default pattern in React, sends something closer to a flat-pack: a minimal HTML shell and a JavaScript bundle. The browser downloads the bundle, executes it, fetches data from an API, and only then assembles the page. Rendering in the original sense happens last, after all of that.
For a highly interactive application, this sequence makes sense. For a site whose primary job is to carry text from a writer to a reader, it introduces an invisible wall between the content and anyone trying to reach it.
The industry correction
Search engines hit that wall first. Googlebot would arrive at a React site, find an empty shell, and either wait for JavaScript execution or index nothing. Developers built workarounds. React added server-side rendering as an option. Next.js made it the architecture, turning React from a client-side library into a full framework capable of generating HTML on the server. Later still, React Server Components went further: components that run only on the server and never ship JavaScript to the client at all. The ecosystem spent years building infrastructure to fix a mismatch between the tool and the use case.
The cost was real. DoorDash's original React frontend grew until the JavaScript bundle became, in their own engineering team's words, difficult to optimise. Pages would show a blank screen while the browser waited to finish assembling them. Users saw nothing, then everything, with an uncomfortable gap in between. They migrated to Next.js page by page, and the improvement was immediate: pages loaded with content visible from the first response, the way a server-rendered site always had. That is what the invisible wall costs at scale.
The publishing tools that got this right were server-rendered from the start. The content is in the HTML on first response. No JavaScript execution required to read it. Many of them run on Node.js, the same runtime that powers the broader JavaScript ecosystem. The difference is what they use it for: assembling HTML on the server before anyone arrives, not shipping the assembly work to the browser.
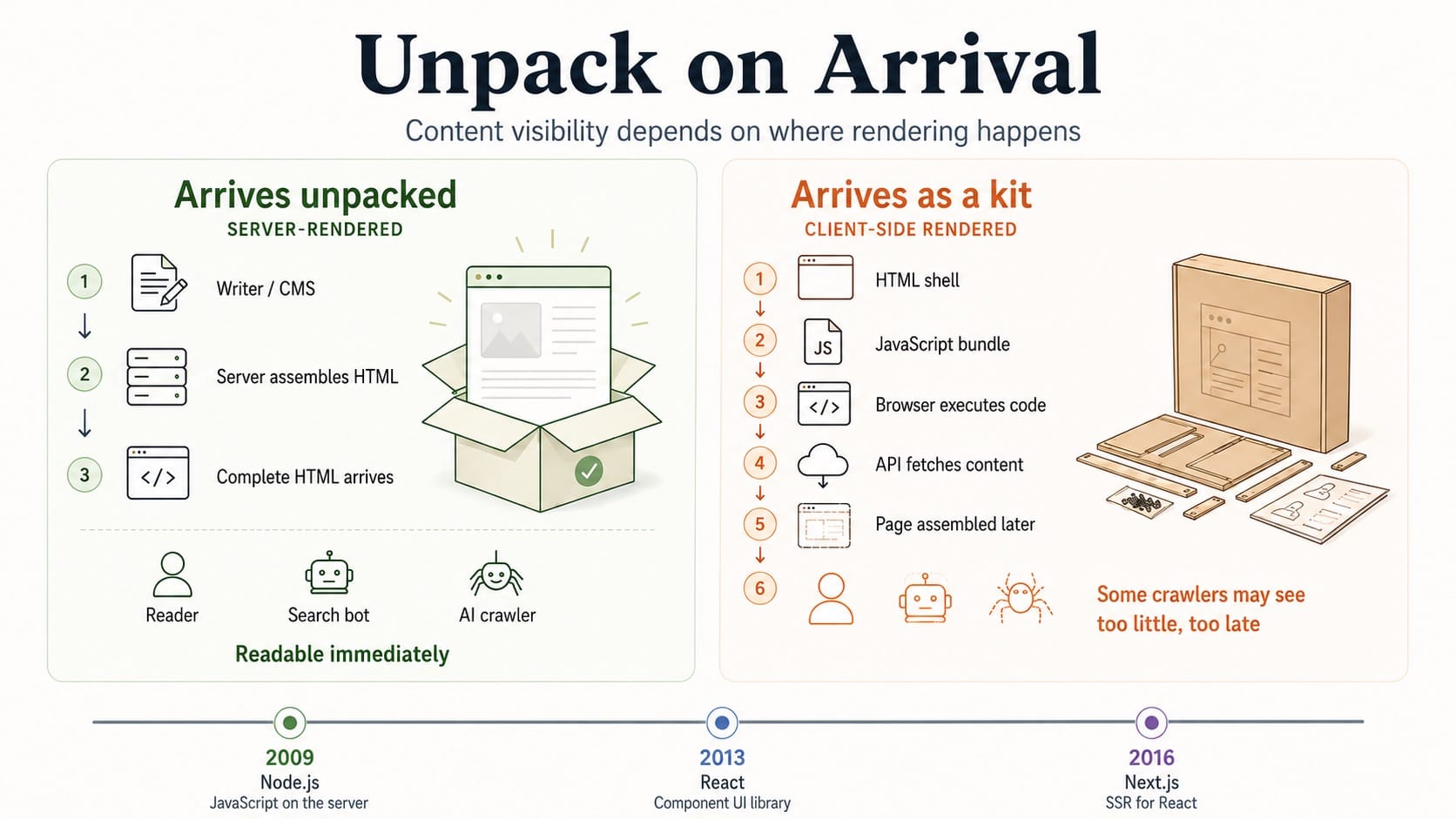
The same wall, new visitors
AI crawlers have the same limitation search bots always had. They read HTML. They do not reliably execute JavaScript. A React site that was half-invisible to Google is equally invisible to the systems building the retrieval indexes behind Perplexity, ChatGPT, and Claude.
The stakes are slightly different now. With search, poor rendering meant a lower ranking. With AI retrieval the dynamic is more binary: either the content was there when the crawler arrived, or it was not. There is no page three. Either your writing contributed to the answer, or it did not exist.
I have been doing deliberate work on this side of things: llms.txt to signal what is here and how to use it, content cached and served as plain markdown via a Cloudflare Worker so machine readers can find the cleaner format. That work only makes sense if the content is actually present in the first place. The architecture has to be right before any of the signalling matters.
What the developers were solving
The JavaScript-first instinct was not wrong. React solved real problems: rich interactivity, stateful interfaces, products that behave like applications. The problem was category drift. The same approach got applied to publishing, to marketing sites, to anything built by a team that knew React well and reached for the familiar tool.
The developers I argued with were not wrong about their frameworks. They were wrong about what a content site needed from its architecture. Those are different questions, and for a long time the industry treated them as the same one.
My instinct was about content, not frameworks. Content needs to be there when someone arrives: human or machine, search bot or AI crawler, fast connection or slow one. Everything else is optimisation.
The AI era did not change that requirement. It just made the cost of getting it wrong more visible.
Further reading
- Markdown: the WD-40 of Digital Information -- on why markdown has outlasted everything built around it
- llms.txt -- signalling to AI systems what your site is and how to use it
- My Visitors Are Not All Human. That Is Fine. -- on bots as guests, and the distinction between those who identify themselves and those who don't