My Visitors Are Not All Human. That Is Fine.
I built a traffic dashboard for my own site. What I found wasn't alarming, it was interesting. A publisher's notes on bots, borrowed identities, and editorial agency.


My site had a busy week. My analytics tool showed good numbers. Then I looked at the raw traffic logs and started counting visitors that weren't people.
Not a problem. A discovery.
For the past few months I've been running a custom traffic layer on this site, built on top of Cloudflare, which sits between my visitors and my server and sees everything that arrives. I wrote a small classifier that sorts incoming traffic into categories: human readers, crawlers from search engines, crawlers from AI companies, monitoring tools, and a catch-all for things I can't identify. On any given day, humans are a minority.
That sentence used to feel alarming when I first framed it to myself. Now it just feels accurate. If you're curious, the live dashboard is public: hoeijmakers.net/bot-stats.
The old mental model
The web was built around a simple distinction. Humans used browsers. Bots sent raw HTTP requests, usually announced themselves honestly, and showed up cleanly in your server logs with a recognisable name.
That distinction is largely gone.
Modern automation often runs a real browser, the same engine that Chrome uses, and behaves accordingly: it loads the page, executes the code that runs on it, triggers the analytics beacon that tells my dashboard someone visited, scrolls, waits, and moves on. Add a residential proxy network, which routes traffic through actual household internet connections rather than servers in a datacentre, and the request arriving at my site looks indistinguishable from a person in Rotterdam reading an article over their home wifi.
A visit is no longer proof of a visitor.
Borrowed identities
The residential proxy industry routes automated traffic through pools of real consumer internet connections. Millions of them. A client pays to use them; the destination website sees a local address, an ordinary internet provider, nothing suspicious. It sees, in other words, a person.
This infrastructure serves legitimate purposes: checking whether an ad actually appeared in a specific country, testing how a website looks from different locations, monitoring competitor prices. It also serves extractive ones. The point is that it is now a normal part of web traffic, running quietly beneath the surface of every publisher's analytics.
What I actually see
My traffic dashboard shows patterns rather than proof. No single signal identifies a visitor as a script rather than a person. Combinations do.
Sessions that load a page and vanish, with no onward movement, no return visit, no sign of reading. Visitors arriving from a wide spread of countries with identical behaviour. Entry pages that cluster unnaturally: always the homepage, never a deep link from a real referrer. Requests arriving at suspiciously regular intervals.
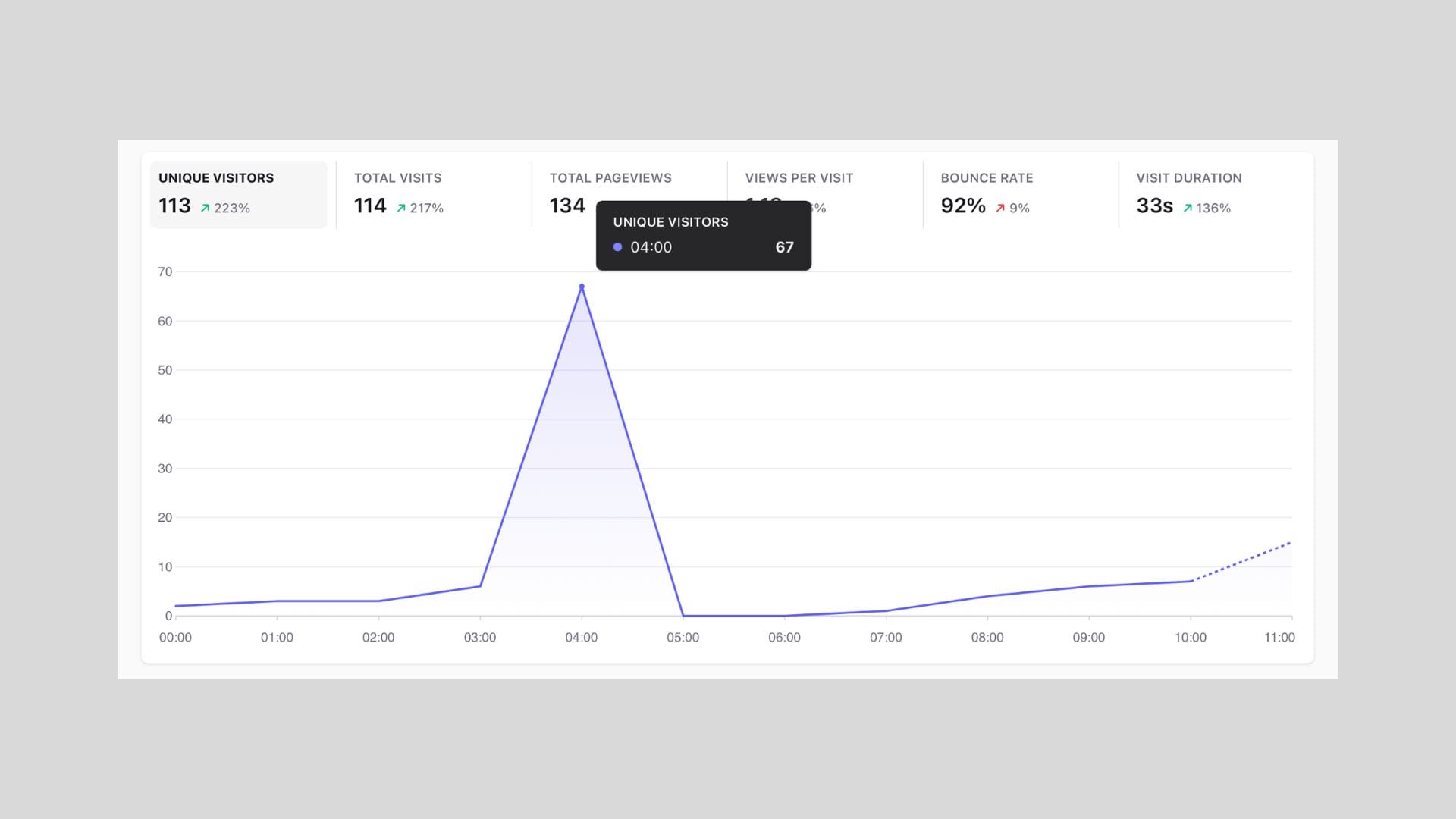
Some of this traffic is fine. Search crawlers indexing my writing are doing something useful. Crawlers from AI companies reading my articles are, in some sense, a new kind of audience. I've added a small index file to the site specifically to help them navigate it more cleanly.
Some of it I decided not to serve. Amazon's infrastructure was generating substantial crawl traffic with no plausible return. I blocked it. Not in outrage: as a quiet editorial decision. My content, my choice about who reads it.
That act of blocking felt unexpectedly good. Not because of what it prevented, but because of what it clarified. I have a position on this. I can act on it.
The logfile returns
There is a generation of web publishers who learned to read raw server logs before dashboards existed. They knew their traffic intimately. Dashboard analytics, when it arrived, abstracted most of that away. Traffic became a number, then a graph, then a metric.
Infrastructure like Cloudflare is pulling some of that texture back. It sits in front of the server and sees things browser-based analytics cannot: how fast requests arrive, whether IP addresses rotate, whether a visitor ever fetches images or just the HTML. The signal is different from what a dashboard shows.
I am not claiming logs are more truthful than dashboards. I am noting that they are different, and that the difference is currently interesting.
What audience means now
The web is no longer a medium where humans visit websites. It is a medium where humans, search crawlers, AI crawlers, monitoring scripts, and commercial intelligence systems all arrive through the same door. Some are reading. Some are indexing. Some are training models on what they find. Some are checking whether an ad appeared. Some I cannot classify at all.
My analytics dashboard shows me one version of this. My traffic logs show me another. The honest position is that both are partial.
What I have, with a little tooling and some curiosity, is a better picture than I had six months ago. And the ability to make choices about it.
That is enough.