What llms.txt can do for your website
When bots become interpreters of your brand, context matters. llms.txt helps guide what AI systems understand and repeat about your website.


Language models increasingly act as intermediaries between organisations and their audiences. If a client asks ChatGPT about your services, the response depends on what the model believes to be true about you. Llms.txt offers a simple way to nudge that understanding in the right direction.
When AI becomes a source of truth
More people ask ChatGPT about your organisation than you might expect. The answer they receive is based on whatever the model has learned about you so far. Sometimes that is recent and accurate. Often it is not.
If language models are becoming a practical interface to your services, it helps to offer them a reliable starting point.
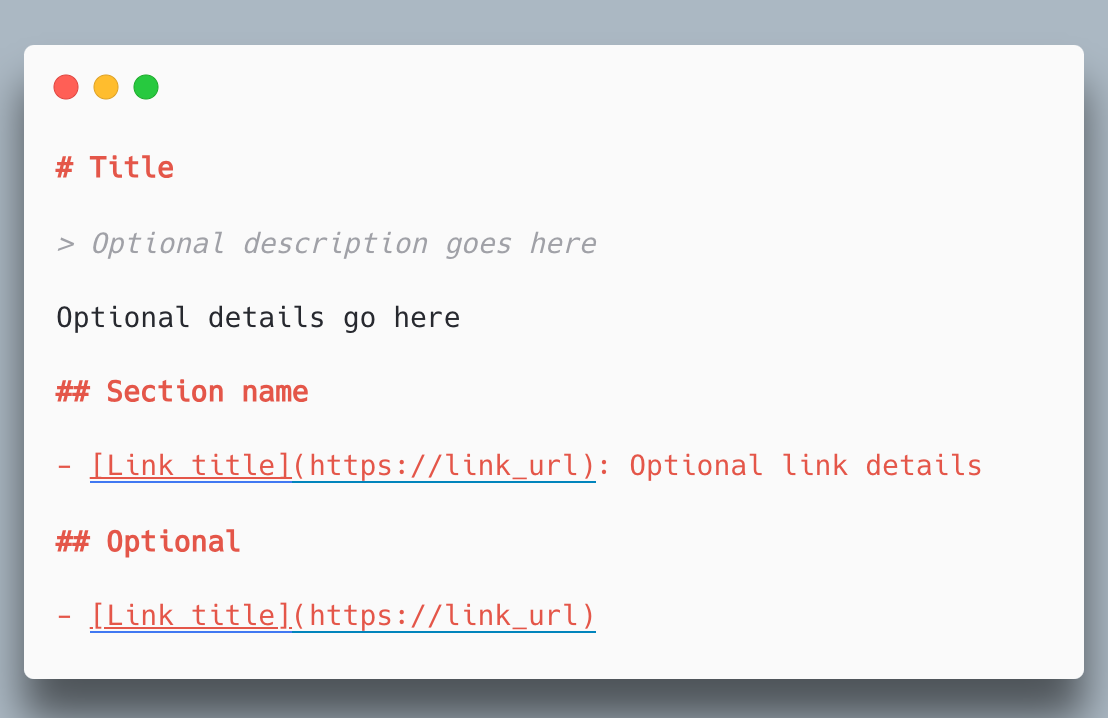
Introducing llms.txt
llms.txt is a simple idea. Just as robots.txt guides search engines, llms.txt offers guidance to language models. It is a plain text file that can describe:
- what your organisation actually does
- which pages or sources are authoritative
- which terms are correct or preferred
It does not give you strict control. It offers context that models can use to avoid guesswork.
This idea is gaining traction. I recently exchanged thoughts with Pieter Versloot from PlateCMS on LinkedIn, who added useful pointers and examples from the CMS perspective. I will include that reference below.

Implementing it in practice
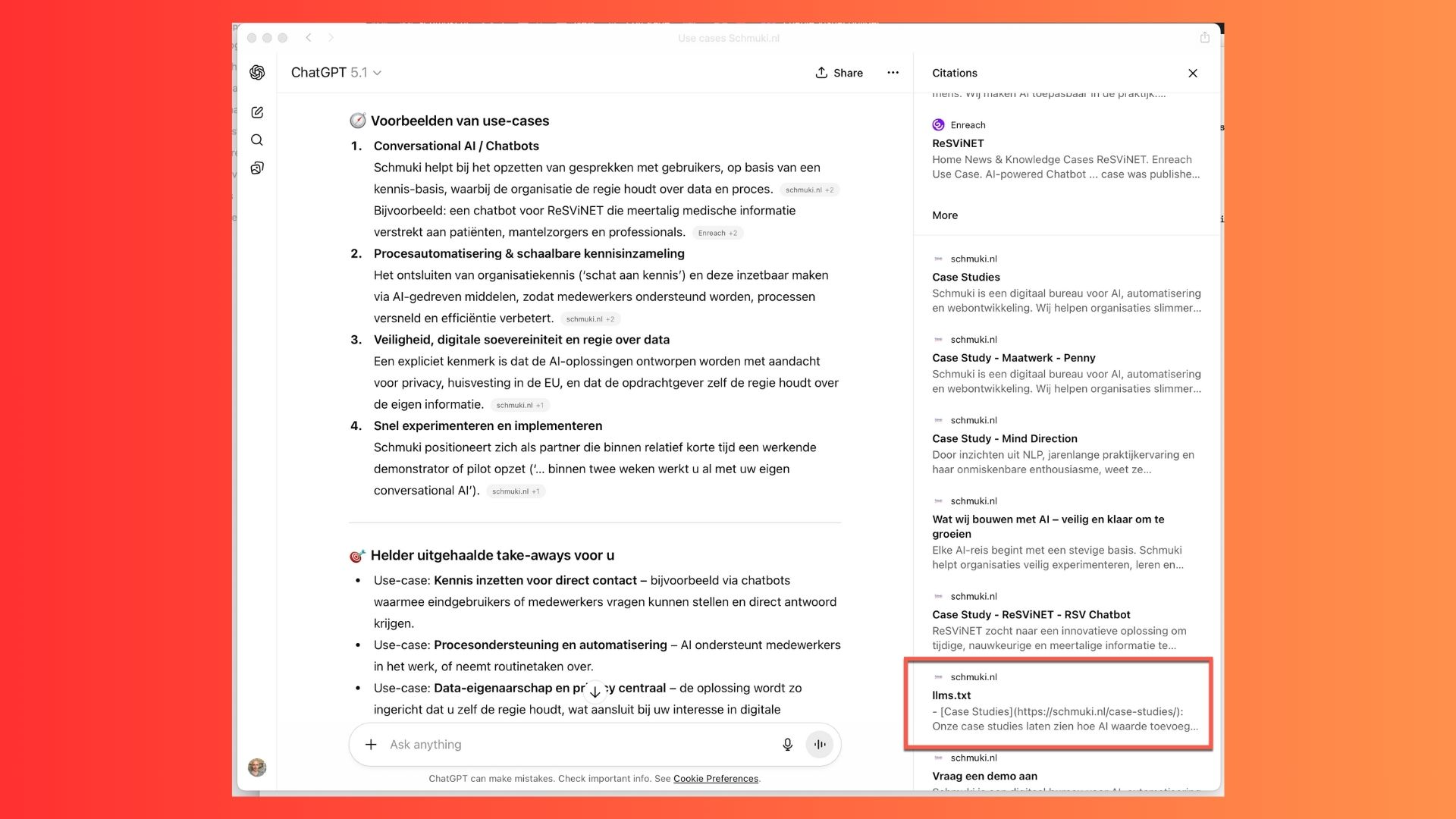
I added llms.txt to our own website to see what happens in the real world. Creating the file was the easy part. Making it reachable turned out to be the real challenge.
My hosting provider Hostinger blocked requests from LLM crawlers by default. The file lived on the server but returned a 403 to any AI agent. It was effectively invisible.
The fix was to move DNS to Cloudflare and let their CDN handle the traffic. Suddenly the file was accessible and visible in analytics, including visits from AI-related bots.
Testing is straightforward. You can simply ask ChatGPT whether it can access your llms.txt. If something blocks access, it will say so and often suggest where the issue might sit.
Why this matters for digital professionals
Your organisation already works hard to keep its messaging consistent. Llms.txt extends that effort to automated systems that summarise you for others.
It will not guarantee perfect accuracy. It provides a baseline, a reference that can reduce outdated assumptions over time.
What I am tracking next
I plan to observe whether the presence of llms.txt influences how AI agents describe our business. If the effect is positive, this practice will likely spread further through the web development and CMS ecosystem.
The main lesson so far is straightforward. The barrier was not writing the file but making sure it is visible to the systems that need it. A small adjustment can prepare your website for a future where AI is often the first audience.