LangWatch: Power of Evals for LLM-Based Systems
When your chatbot changes behaviour overnight, how do you know why? Evals are the missing link between AI intuition and product certainty. I talked to Manouk Draisma from LangWatch.


Introduction: The Problem with “Working” AI
The trouble with live AI systems isn’t that they break in obvious ways. It’s that they drift. A prompt that worked last week might behave differently today. Without warning or error.
Especially when you tweak system instructions, update to a new foundation model, or just change the order of a few sentences. That’s not a bug. That’s how probabilistic systems work.
But when you're responsible for production-grade chatbots, like we are at Schmuki, that uncertainty is a problem. You need to know not just whether something works but whether it's still working, and whether it's working better. Manual checks don’t scale. So what’s the alternative?
That’s where evals come in.
“An eval is a repeatable test that measures the quality and consistency of AI-generated outputs—beyond just accuracy.”
They’re how you make LLM behaviour measurable and manageable.
A Dutch Startup, A Demo, and a Pause
It started when someone pointed me to a small company in the Netherlands called LangWatch, co-founded by Manouk Draisma. They specialise in structured evaluation of LLM outputs. Building evals that track how well prompts, models, and instructions perform over time.
I spoke with Manouk, saw a demo, and was intrigued. But I also needed time. It’s abstract stuff. I agreed to a deeper interview but told her honestly, I needed this to sink in first.
A Podcast That Made It Click
Fast forward a few weeks. I resumed a podcast I had half-finished: Azeem Azhar in conversation with Kevin Weil, Chief Product Officer at OpenAI. And there it was, right in the middle of their conversation, a clear, grounded explanation of how OpenAI uses evals internally to iterate, monitor, and productise complex model behaviours.
“The most effective way to build products,” Weil says, “is to take the skill you want the model to have and turn that into an eval.”
Suddenly, the theory met practice. It wasn’t just about benchmarking. Evals had become the interface between engineering, product, and research.
What Evals Actually Are
An eval is a structured way to test and measure LLM behaviour across different dimensions—accuracy, helpfulness, tone, reasoning, or creativity.
They can be:
- Automatically scored (e.g. through classifiers or models)
- Human-reviewed (e.g. by rating or voting)
- Or hybrid (a bit of both)
But the key feature is this: evals are repeatable. They allow you to measure the impact of changes over time, whether that’s to prompts, models, instructions, or settings.
You can think of them as:
- Regression tests for language models
- Custom benchmarks for your own product criteria
- Signals for when something goes off track. Or gets better
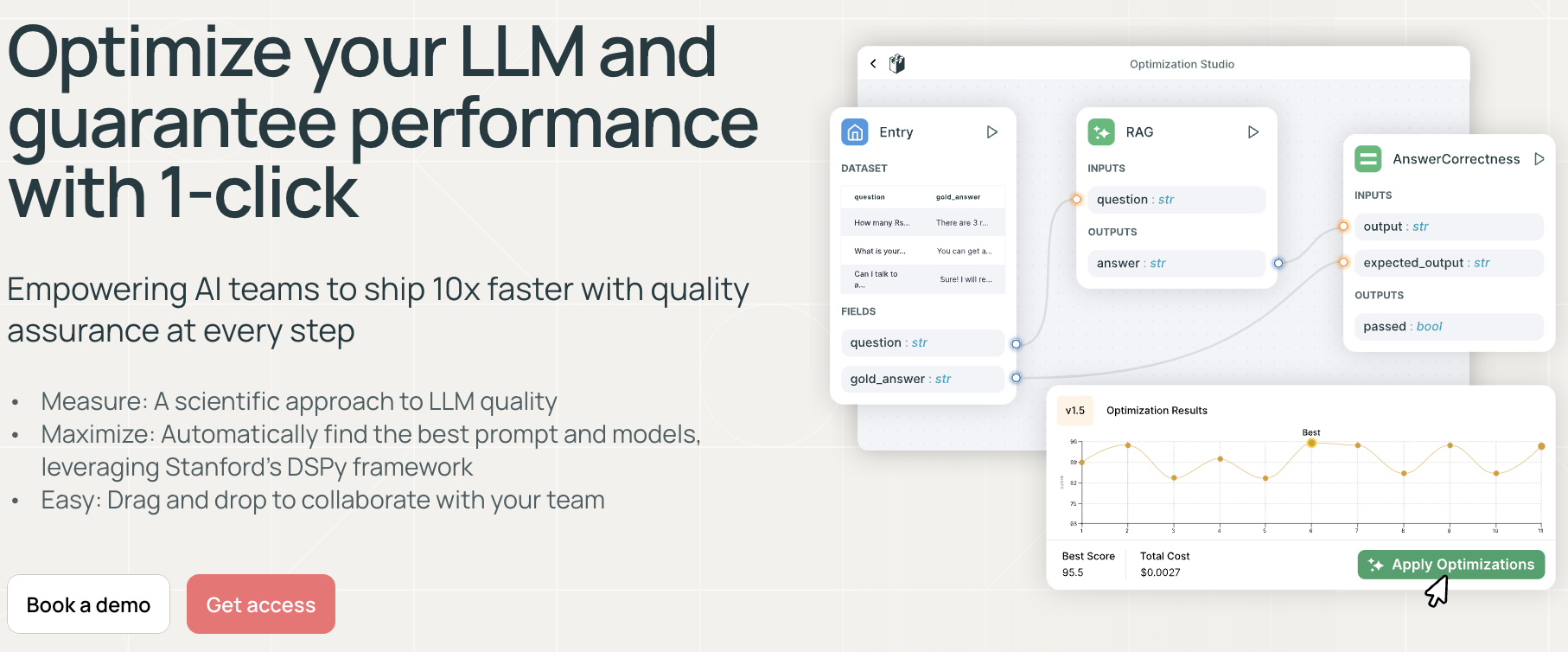
LangWatch: Making This Tangible
LangWatch is building tools that bring evals into real-world practice. Their platform lets you:
- Track model and prompt performance over time
- Compare outputs across versions or experiments
- Get notified when behaviour changes unexpectedly
- Customise what “quality” means for your product
It works like CI/CD for LLMs: continuous monitoring, feedback, and confidence in production. With LangWatch, evals stop being an academic concept and become part of your deployment workflow.
I'll be doing a follow-up interview with Manouk soon to explore how LangWatch works under the hood.
Why Evals Matter (Especially Now)
Evals aren’t just for research labs anymore. They’re becoming essential for:
- Product quality assurance
- Safety and trustworthiness
- Prompt development workflows
- Debugging complex interactions
- Auditing and documentation (especially in regulated sectors)
As more teams deploy assistants, agents, and AI interfaces in production, evals are the missing link between “it seems fine” and “we know it’s working”.
Whether you're managing a customer support bot, an internal tool, or a knowledge assistant, evals help you track what's working and prove it.
If you’re not using evals to monitor your LLM systems, you’re flying blind.
What’s Next
For me, this was a moment where something abstract became practical. The combination of a hands-on demo and a well-timed podcast made it click. And now it’s part of how I think about every chatbot we run.
If you’re building with LLMs, take a moment to look into evals. They’re not just about safety or performance, they’re about building with confidence.
I’ll share more soon in a follow-up conversation with Manouk from LangWatch. In the meantime, I’d love to hear how you measure whether your AI is still doing what it’s supposed to do.