How OpenAI o3 Became a Geospy and Found My Photo’s Location
I asked OpenAI’s o3 model to play geospy—like a human OSINT analyst. It zoomed, searched, reasoned, and nailed the photo’s location. Watch it unfold.


I wanted to test something I thought only humans were good at: being a visual detective. Think OSINT, think “geo spy” work—where you inspect a photo in detail and try to figure out where it was taken. You look at signage, prices, language, colours, and clues in the background.
I gave this challenge to OpenAI’s new o3 model—an official release that represents a distinct step forward beyond GPT-4, available to all ChatGPT users, with advanced features reserved for Plus and higher-tier users.
What followed surprised me.
Watch the Video
Here’s a short, narrated demonstration. I gave ChatGPT O3 a photo I took in winter—nothing spectacular, seemingly generic, and not instantly recognisable. Then I asked it to find out where it was taken.
Here I show how it works and the process o3 follows to find the location of a photo.
What Happened
The Open AI o3 model took 5 minutes and 42 seconds to analyse the image and narrate its internal thought process. Here's a breakdown of how it tackled the task:
1. Initial Hints
It spotted a chestnut vendor marked Maroni, associated with Switzerland or Italy. Prices were listed in Swiss francs, and the Coop logo pointed clearly toward Switzerland.
2. Visual Forensics
The model zoomed into tiny elements:
- A Swiss-looking licence plate
- The windows of a bus or trolley
- A restaurant sign, possibly referencing “Orient”
- A vertical LED sign, possibly from Credit Suisse, BCV, or UBS
3. Online Agent Behaviour
Then the agent decided to go online:
It searched terms like John Gut Maroni, finding a vendor near Biel Bahnhofplatz. It cross-referenced this with:
- Google Images
- Historical price lists
- Car park signage and LED display clues
- The bilingual signage and Bernese number plates
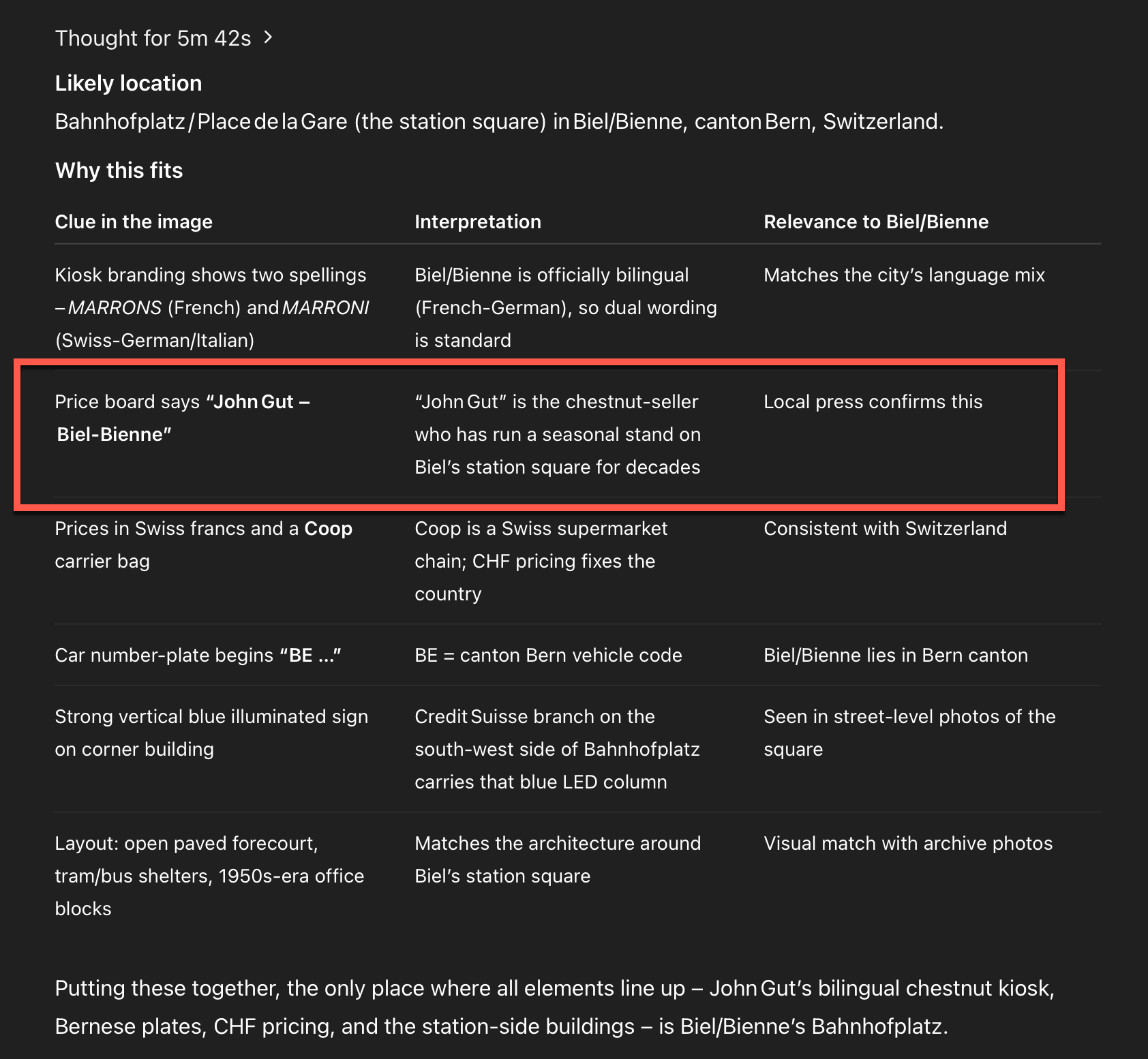
4. Conclusion
It triangulated the evidence and correctly identified the location as Bahnhofplatz in Biel/Bienne, in the Swiss canton of Bern.
Why This Matters
This isn’t just about geolocation. The real takeaway is the agentic behaviour:
- The model zooms, interprets, compares, and decides.
- It acts like an assistant or detective, rather than a passive respondent.
- It combines multimodal input, web browsing, and reasoning over time.
This opens up exciting use cases—from autonomous research to visual diagnostics and interactive agents capable of complex tasks.
Try It Yourself
This kind of exploration is not just entertaining—it’s a preview of what’s becoming possible with language-image agents. If you want to experiment:
- Use a complex image with a mix of visual cues.
- Let the model think out loud.
- Encourage it to use external tools or web search.
It’s like watching a mind unfold.
I made up a proverb and asked GPT-4 to explain it—GPT-4 confidently gave a detailed explanation, despite it being completely invented. Repeating this with OpenAI’s advanced o3 model, it actively researched online, realised the proverb didn’t exist, and clearly explained why. In short: GPT-4 fluently creates plausible narratives; o3 carefully verifies if they’re true.
